
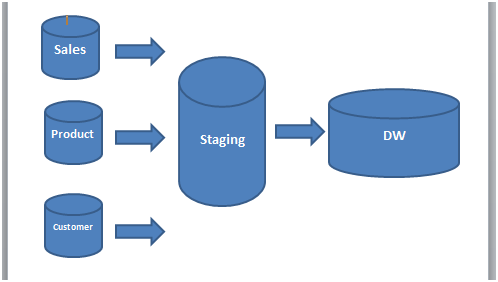
In the last article we talked about ETL and its importance regarding migration and data integration. Let’s continue the subject, but this time, talking about the Staging Area that is a concept very important so that you can have an ETL process well done.
Just at the review level, you remember that in ETL we do:
- The extraction of data from a Source, which can be a TXT file to a database;
- We have the Transformation process, which is where data is handled to be directed to the target repository;
- We have the Load, which is the process of entering the destination trno data.
To illustrate the Staging Area, I’ll use the same image used in the ETL article to show how this feature is in the process.
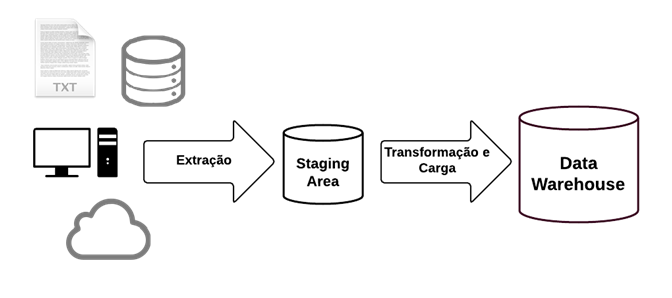
The Staging Area is a temporary location where data from the source systems is copied. In this way, instead of accessing the data directly from the source, the ETL “transformation” process takes the data from the Staging Area to process and deliver the data.
In some cases, instead of “Staging” being a temporary table it can be a materialized view that can be executed (manually or by load scheduling) to have the data always updated.
Since some projects need to have multiple data sources, the need to have a STAGING becomes mandatory so that you can gather as much data as possible and thus be able to select the data by transforming it into information.
The benefit of this feature is being able to store the data in its “raw” source so that you can work on them instead of always having to access the Data Source. This way you can avoid a lot of problems, like low performance for example. In addition, you have the security that the data will be at your disposal until you execute some process that clean the STAGING.
Let’s take an example
Suppose you have to query 3 different tables (such as data source) to generate
information that will feed a dashboard. This dashboard is consumed daily by a team of executives and so they need to be always up to date.
It turns out that the information that is extracted from the Source are lost from time to time and, if you need some recovery at the source, it would not be possible since the information is external where you do not have a domain.
If so, what would you do to keep the data history?
Very simple. It would build a “Staging Area” to store the information of the Source and begin to use it in the project. Notice the flow below:
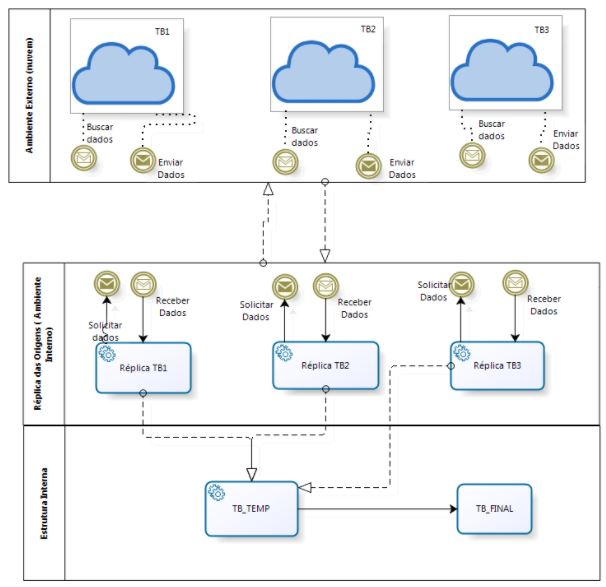
Note that we access the source tables to fetch the data and store it in STAGE’s, which we call REPLICA. These Replicas were accessed by another Staging that gathered the information from the 3 tables and, after processing / processing the data, delivered to the Destination (TB_FINAL).Note that we access the source tables to fetch the data and store it in STAGE’s, which we call REPLICA. These Replicas were accessed by another Staging that gathered the information from the 3 tables and, after processing / processing the data, delivered to the Destination (TB_FINAL).
Well, that’s it, I’m staying here.
Doubts ???? Contact
Strong hug.
Eduardo Santana
bufallos@bufallos.com.br