

Neste artigo, falaremos sobre o Controle das Sessões e das Fios para versão paralela do carro não ODI 12c.
No artigo passado, Veja como melhorar a performance na carga de dados com ODI 12c , escreva sobre uma execução paralela não ODI, que é uma forma padrão de ser executada. Falamos também do benefício que o paralelismo dá ao executar mapeamentos que contenham Fontes distintas sendo executadas ao mesmo tempo, assim como falamos também, o quanto que o Paralelismo pode consumir de sua infraestrutura.
Bom, depois de entender como funciona um mapeamento que roda cargas paralelas, fácil de ver que para cada fonte distinta você terá uma sessão distinta , logo, quanto mais cargas com origens ou destinos diferentes mais sessões você terá que usar para executar um único mapeamento.
Acontece que para executar um mapeamento você precisa, implicitamente, executar 3 processos que são:
1 – Chamar o Agente que executeará seu mapeamento;
2 – Uma sessão (ou várias sessões, automaticamente);
3 – Iniciar Threads que serão utilizadas para rodar o mapeamento.
PS : Lembramos que o AGENTE criado no ODI, são processos Java que orquestra a execução de objetos em tempo de execução.
Isso significa que uma execução de um mapeamento altamente paralelizado pode levar um número elevado de threads, que esgotarão todos os recursos do sistema .
Então, pergunte-me: Como fazer para que possamos executar mapeamentos que não sobrecarreguem nossos recursos?
Para responder esta pergunta sugiro as seguintes medidas:
1 – Customização do Agente Físico
O ODI oferece duas formas para controle de Threads, são elas:
• Controle do número máximo de threads NO AGENTE;
• Controle da contagem máxima de threads dentro de uma sessão.
Para acessar os campos que podem ser customizados, abra seu Agente Físico e altere os valores, conforme imagem abaixo:
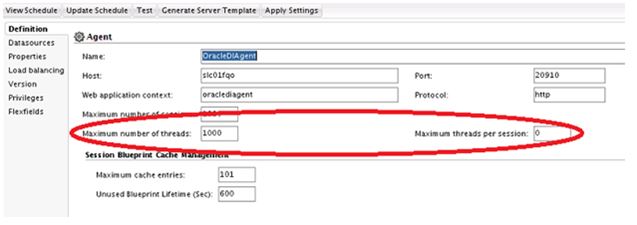
Desta forma, você terá um controle muito mais eficiente e evitará a degradação de seus recursos / sua infraestrutura.
2 – Planeje sua Carga de Dados
Quando você está diante de um processo de mapeamento para executar cargas de dados, é muito importante que você faça um planejamento de como esta carga será executada.
No curso, Aprenda a fazer Migração de dados com o ODI 12c, tem uma aula que falo sobre este assunto.
Quando você planeja uma carga, você pode, por exemplo, fazer com que o mapeamento DEFAULT (para a carga principal) possa puxar ou jogar os dados em um lugar só e você pode fazer isso da seguinte forma:
Suponha que você tem 3 tabelas distintas, inclusive em servidores diferentes, e precisa carregar dados de todas elas ( fazendo um merge de dados) em uma tabela única de destino.
O que você poderia fazer para não ter tantas Threads / Sessões iniciadas?
Você pode criar STAGEs ( tabelas temporárias na mesma estrutura de sua tabela de DESTINO) que podem armazenar os dados que você quer ( carga bruta) e no seu mapeamento principal, você utilizar apenas de 1 recurso de ORIGEM (Tabela ou View Materializada) e executar seu mapeamento consciente de que o uso de Threads / Sessões é o mínimo possível.
Além dessas sugestões existe um outro recurso que também é muito importante e que foi disponibilizado na versão 12c do ODI que é o recurso de CÓPIA DE SESSÕES.
Na versão 11G do ODI, quando ele utilizava de cenários para executar cargas programadas, ele precisava ficar acessando os dados do REPOSITÓRIO para recuperar todas as etapas e tarefas que deve executar a partir do repositório e gerar logs antes de começar a executar qualquer coisa.
No ODI 12c, o agente agora só recupera um Session Blueprint uma vez e o mantém em cache. Como é armazenado em cache no agente, não há necessidade de obter nada do repositório se o trabalho for executado novamente alguns minutos depois. O agente gera apenas os logs necessários definidos pelo nível de log, já que ele depende apenas do plano de execução e não dos logs. Os parâmetros relacionados aos planos estão disponíveis na definição dos agentes físicos na topologia.

Em resumo, graças aos Modelos de Sessão, uma sobrecarga da sessão de execução é bastante reduzida. O agente precisa recuperar menos dados do repositório. Isto não é fantástico?
Pessoal, fico por aqui. Espero ter ajudado.
Tendo dúvidas, é só chamar.
Forte abraço.
Eduardo Santana
bufallos@bufallos.com.br