
Hoje em dia, qualquer projeto que você desenvolver deve ser feito com olho na performance de sua infraestrutura. Isso, por que não adianta você desenvolver um baita de um projeto e ele ser custoso pra sua empresa.
Pensando nisso, decidi escrever 2 artigos no qual falarei sobre Melhoria de Performance com o Oracle Data Integrator 12c.
O primeiro tema a ser abordado será o Paralelismo na Sessão de execução do ODI 12c e o segundo falarei sobre o Controle de Sessões e Threads pelo ODI 12c.
Com a nova versão do ODI 12c, a Oracle implementou uma camada de inteligência onde o ODI identifica automaticamente as sessões que podem ser executadas simultaneamente e gera o código pra sua execução paralela.
Por exemplo, na camada de ORIGEM (SOURCE) você precisa buscar dados de fontes totalmente distintas. Acontece que essas fontes irão alimentar o mesmo destino. O que o ODI faz? Ele junta as duas fontes (que estão em servidores diferentes) na mesma sessão, conforme imagem abaixo.
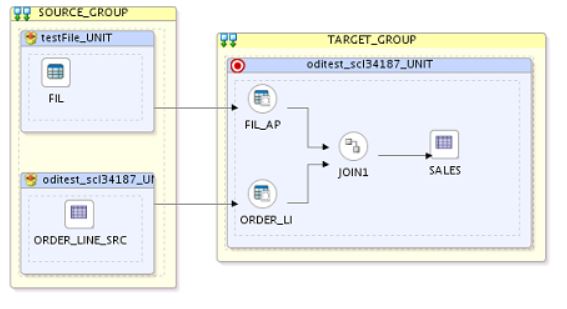
Desta forma, ele executa o processamento da carga fazendo paralelismo.
Bom, o que pra muitos isto pode parecer como algo muito bom já que tudo será executado ao mesmo tempo e pode parecer um processo otimizado, eu vejo como algo delicado. Por que o uso de paralelismo, nessas condições onde as FONTES estão em lugares distintos, é justamente um dos motivos que fazem com que sua performance caia.
Imagine se você tiver que fazer vários mapeamentos semelhantes ao que foi mostrado na imagem e além disso este mapeamento estiver em modo de execução automática ( obedecendo alguma regra de negócio / schedule / cenário ) que deve executá-lo de hora em hora. Seu servidor não vai guentar.
Para solucionar isso, recomendo que (como boa prática), você separe as FONTES (Tabelas) para que cada uma tenha sua própria unidade na sessão, como na imagem abaixo .
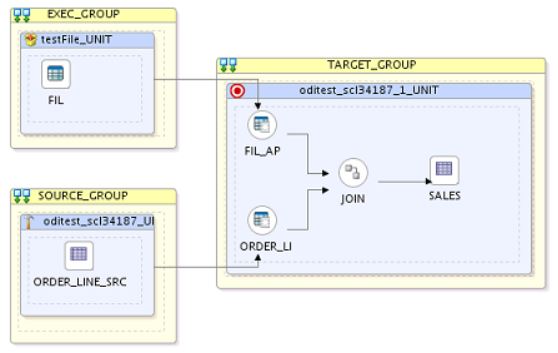
Desta foram, o ODI irá entender o que você está querendo fazer. Ele irá executar os processos de forma sequencial analisando qual deve rodar primeiro. Assim, seu processo ficará muito mais leve e rápido sem degradar a performance de sua infraestrutura.
Além disso, existe um ponto interessante a ser abordado nesta questão do paralelismo que é o “Gerenciamento das Conexões”.
Por que estamos abordando que manter o paralelismo nos mapeamentos prejudica sua performance ?
Cada mapeamento quando está em modo de execução paralela, assume que cada tarefa terá sua própria conexão a partir do Pool de Conexões. Por isso, se você tiver mapeamentos altamente paralelos, o tamanho do pool de conexões deve ser de acordo com o nível de paralelismo. Ou seja, você irá ter mais de uma conexão para executar o mesmo mapeamento ( carga de dados).
Existem três pontos que podemos citar como candidatos ao Paralelismo ( que você pode evitar) que são:
1 – Quando os dados de Origem são carregados na área de teste;
2 – Quando os dados estão em Origens distintas;
Sacada : Você pode criar uma Staging Area pra carregar os dados que precisa e executar a carga em uma estrutura só.
3 – Quando os dados precisam alimentar vários Destinos;
Acredito que adotando essas boas práticas você terá um excelente mapeamento e uma otimização de processamento muito satisfatória.
Pessoal, fico por aqui.
Tendo alguma dúvida, entre em contato.
Forte abraço.
Eduardo Santana
bufallos@bufallos.com.br