
No artigo passado falamos sobre ETL e sua importância no que tange migração e integração de dados. Vamos dar continuidade ao assunto, mas desta vez, falando sobre a Staging Area que é um conceito
muito importante para que você possa ter um processo ETL bem feito.
Só a nível de revisão, vocês lembram que no ETL nós fazemos :
- A extração dos dados de uma Fonte, que pode ser um arquivo TXT a uma base de dados;
- Temos o processo de Transformação, que é onde os dados são tratados para serem direcionados para o repositório de destino;
- Temos o Carregamento, que é o processo de inserir os dados trno destino.
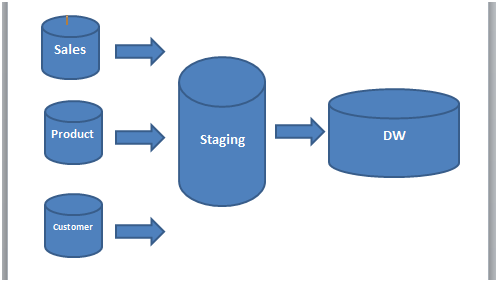
Para ilustrar a Staging Area, usarei a mesma imagem utilizada no artigo sobre ETL para mostrar como este recurso está dentro do processo.
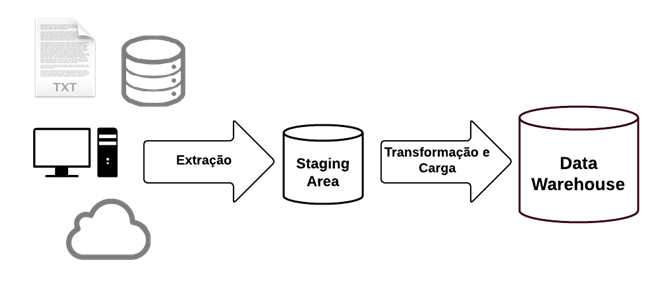
A Staging Area é uma localização temporária onde os dados dos sistemas de origem são copiados. Desta forma, ao invés de acessar os dados diretamente da fonte, o processo de “transformação” do ETL pega os dados da Staging Area para tratar e entregar os dados.
Em alguns casos, ao invés da “Staging” ser uma tabela temporária pode ser uma view materializada que pode ser executada ( manualmente ou mediante programação de carga) para ter os dados sempre atualizados.
Como alguns projetos precisam ter várias fontes de dados, a necessidade de termos uma “STAGING” acaba sendo obrigatório para que você possa reunir o máximo de dados possível e, com isso, poder selecionar os dados transformando-os em informação.
O benefício deste recurso é poder armazenar os dados em sua origem “bruta” para poder trabalhar em cima deles ao invés de ficar sempre tendo que acessar a Fonte de dados. Assim você consegue evitar uma série de problemas, como baixa performance por exemplo. Além disso, você tem a segurança que os dados estarão a sua disposição até que você execute algum processo que limpe a STAGING.
Vamos a um exemplo
Suponha que você tenha que consultar 3 tabelas diferentes ( como fonte de dados) para gerar
uma informação que alimentará um dashboard. Esse dashboard é consumido diariamente por uma equipe de executivos e por isso precisam estar sempre atualizados.
Acontece que as informações que são extraídas da Fonte são perdidas de tempos em tempos e, caso seja necessário alguma recuperação na fonte, não seria possível já que as informações são externas onde você não tem domínio.
Nesse caso, o que você faria para manter o histórico dos dados?
Muito simples. Construiria uma “Staging Area” para armazenar as informações da Fonte e passar a usá-la no projeto. Observe o fluxo abaixo:
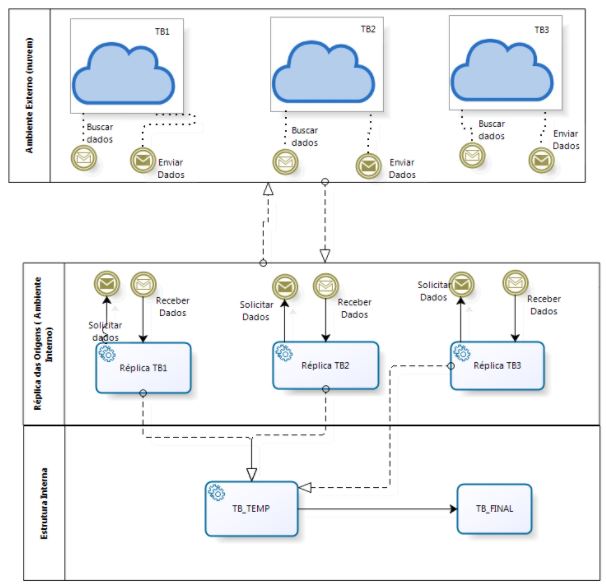
Observe que nós acessamos as tabelas de origem para buscar os dados e armazenar nas STAGE’s, que chamamos de REPLICA. Essas Replicas eram acessadas por outra Staging que reunia as informações das 3 tabelas e, depois de transformar / tratar os dados, entregar no Destino ( TB_FINAL).
Bom, é isso, vou ficando por aqui.
Dúvidas ???? Entre em contato.
Forte abraço.
Eduardo Santana
bufallos@bufallos.com.br